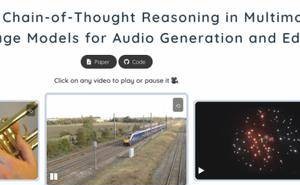
阿里巴巴通义实验室近期宣布了一项重大开源成果——音频生成模型ThinkSound。这一创新模型首次将CoT(思维链)技术应用于音频生成领域,使AI系统能够模拟专业音效师的工作流程,精确捕捉视觉细节,并生成与视频画面高度同步的高保真音频。
ThinkSound的代码与模型已在GitHub、HuggingFace以及魔搭社区等平台开放,供全球开发者免费下载与使用。这一举措旨在推动视频生成音频(V2A)技术的进一步发展,为多媒体编辑和视频内容创作领域注入新的活力。
V2A技术在多媒体行业中占据重要地位,但现有技术仍面临诸多挑战。例如,许多V2A系统难以深入理解视觉与声学细节之间的对应关系,导致生成的音频往往缺乏个性化和时序准确性,难以满足专业创意场景的高要求。为了克服这些难题,通义实验室将思维链推理引入多模态大模型,实现了对视觉事件与声音之间深度关联的精准建模。
该团队还精心构建了AudioCoT数据集,这是首个带有思维链标注的音频数据集。该数据集融合了超过2500小时的多源异构数据,为模型在音频生成与编辑任务中提供了丰富的训练素材,确保了模型在处理复杂音频场景时的准确性和可靠性。
在开源的VGGSound测试集上,ThinkSound展现出了卓越的性能。其核心指标相比MMAudio、V2A-Mappe、V-AURA等现有主流方法均实现了显著提升,特别是在openl3空间中的Fréchet距离上,ThinkSound的成绩接近真实音频分布,相似度提高了20%以上。在代表模型对声音事件类别和特征判别精准度的KLPaSST和KLPaNNs两项指标上,ThinkSound也取得了同类模型中的最佳成绩。
在MovieGen Audio Bench测试集上,ThinkSound同样表现出色,大幅领先于meta推出的音频生成模型Movie Gen Audio。这一结果表明,ThinkSound在影视音效、音频后期处理、游戏与虚拟现实音效生成等领域具有广阔的应用前景。
除了ThinkSound之外,通义实验室还推出了语音生成大模型Cosyvoice和端到端音频多模态大模型MinMo等创新成果。这些模型共同构成了通义实验室在语音合成、音频生成、音频理解等领域的全面布局,为行业用户提供了更加丰富和高效的解决方案。