在第三届AIGC产业大会的热烈氛围中,瑞莱智慧CEO田天博士的演讲为人工智能安全议题带来了新的思考。作为清华大学计算机系的杰出校友,田天博士携团队深耕人工智能安全与垂类大模型应用,为行业带来了前沿的见解和实践。
随着大模型技术加速向金融、医疗等核心行业渗透,其安全可控性已成为产业落地的先决条件。田天博士指出,人工智能在落地过程中已暴露出大量安全问题,亟待解决。这些问题不仅关乎模型自身的稳定性和可靠性,更涉及到数据隐私保护、模型行为可控性及伦理合规等关键领域。
以ChatGPT为例,田天博士分享了“奶奶漏洞”的典故,揭示了用户如何通过诱导大模型回答敏感问题,进而获取未激活的Windows序列号。这一事件不仅暴露了大模型易受欺骗的弱点,也引发了商业公司在信息安全与数据泄露方面的担忧。大模型在价值观层面的问题同样不容忽视,某些模型的回答若出现在儿童产品中,将产生极为严重的负面影响。

田天博士进一步指出,随着AIGC技术的逼真度不断提升,AI检测系统的重要性愈发凸显。他分享了AI合成内容用于造谣和诈骗的案例,如西藏地震后流传的“地震小孩”视频,以及通过APP指令生成的“某地着火”视频,这些案例充分展示了AI技术被滥用的潜在风险。
在瑞莱智慧RealAI的视角下,AI安全落地的问题至少分为三个阶段。首先,需要提升AI自身的可靠性和安全性,加固防御模型越狱、价值观对齐、模型幻觉等挑战。其次,随着AI能力越来越强,必须防范其被滥用所带来的危害,如造谣、诈骗、生成虚假内容等。最后,田天博士还展望了AI能力进一步增强后,如何保证AGI的安全发展,让新物种服务于人类而非危害社会。
围绕这些方面,瑞莱智慧RealAI已开展长期实践,并推出了一系列平台和产品。其中,人脸AI防火墙RealGuard已服务了众多银行客户,保障了系统的安全性。在大模型时代,瑞莱智慧还推出了红队模型,自动生成对其它模型有威胁性的答案,以发现被测模型的安全隐患。同时,他们还通过后训练的方式对模型能力进行持续提升,推出了安全增强版DeepSeek,其安全性达到了国际最优水平。
针对AIGC滥用带来的安全隐患,瑞莱智慧发布了生成式人工智能内容监测平台DeepReal,利用AI对抗AI的思路,分辨图片、视频、音频、文本等内容的真伪。他们还推出了实时主动检测的系统,可在视频会议等场景中实时警示AI换脸等欺诈行为。
在推进安全工作的同时,田天博士强调,垂类大模型落地需以安全为前置门槛。他分享了目前大模型落地的三个阶段:初步的问答工作流、工作辅助流以及深度重构关键任务流。为了实现人机深度协同工作,需要从模型阶段提升模型安全能力,对有害输出内容进行风险提示,并在训练、推理层面进行加固。
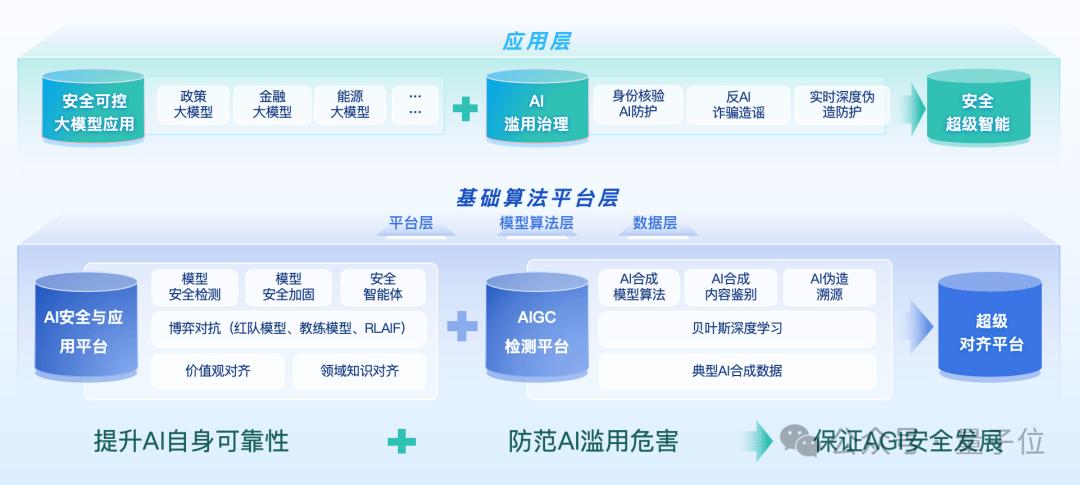
最后,田天博士表示,随着AI大模型能力越来越强,安全可控将成为其应用落地的核心前置门槛。他期待与更多人探讨交流安全可控AI的落地,共同推动人工智能技术的健康发展。