阿里巴巴通义实验室近期推出了一项重大技术突破,开源了名为HumanOmniV2的多模态推理模型。
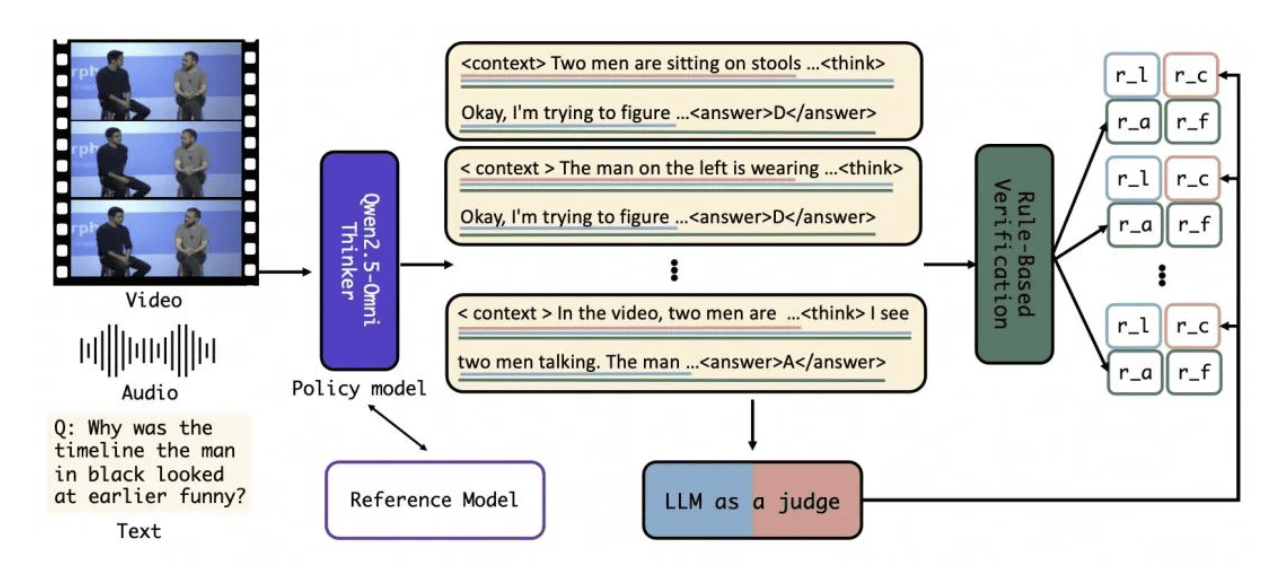
HumanOmniV2通过一系列创新机制,显著提升了对多模态信息的理解能力。该模型不仅引入了强制上下文总结机制,还采用了大模型驱动的多维度奖励体系,并结合基于GRPO的优化训练方法,有效解决了多模态推理中常见的全局上下文理解不足和推理路径简单的问题。

HumanOmniV2在处理多模态信息时,能够系统性地分析视觉、听觉和语音信号,确保不遗漏任何隐藏信息。例如,在回答“女人为什么翻白眼”的问题时,该模型能够综合视频和音频信息,准确判断翻白眼是对潜在敏感话题的夸张反应,而非对他人不满。
为了验证HumanOmniV2的性能,阿里巴巴通义团队还推出了包含633个视频和2689个相关问题的评测基准IntentBench。在此基准上,HumanOmniV2的准确率达到69.33%,展现了强大的多模态推理能力。
HumanOmniV2在多模态推理方面的优势在于其能够结合上下文、音视频背景信息,读懂人物的“话外音”。在一个视频场景中,当询问模型视频中人物过去一年中最难忘的经历及是否说谎时,HumanOmniV2不仅分析了人物的肢体语言和面部表情,还结合了环境、语气等视觉和听觉因素,得出了更为准确的判断。
HumanOmniV2在推理过程中能够捕获更为细粒度的视频和音频线索,如语气变化、表情细节等,从而更准确地理解人物关系和情绪状态。在一个电视采访节目中,模型通过分析人物的语气和表情,成功判断了两人的关系。

HumanOmniV2的成功不仅在于其技术创新,还在于其对多模态推理训练的深入探索。为了解决缺乏大规模人工标注推理数据的问题,阿里巴巴通义团队开发了一个全模态推理训练数据集,融合了图像、视频和音频等多种任务的上下文信息。同时,为了评估模型的性能,团队还推出了IntentBench基准测试,旨在全面评估模型理解复杂人类意图和情感的能力。