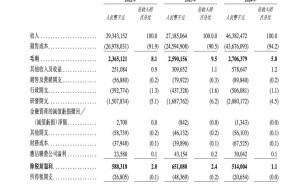
华为创始人任正非近期在一次访谈中展现出了对芯片问题的坚定态度,他表示,通过“叠加和集群”等创新手段,华为的计算实力已能与世界顶尖水平相抗衡,无需过分忧虑。
在全球半导体行业的激烈竞争和技术封锁日益严峻的背景下,任正非的这番言论无疑给人们带来了一线希望。那么,面对芯片制程的差距,华为究竟是如何拥有这份底气的呢?
任正非提到的“叠加和集群”策略,其核心在于通过系统级创新来弥补单个芯片性能的不足。具体来说,集群计算通过高效的网络连接,将多块性能稍弱的芯片协同起来,共同完成复杂任务,从而形成一个强大的整体算力。以华为的昇腾910B芯片为例,尽管在制程上不及国际领先的3nm芯片,但通过自研的CCE通信协议,昇腾芯片能够构建起高效的集群,成功支持了盘古大模型的训练,整体算力可媲美部分顶级GPU。
这种“以量补质”的策略在科技企业中得到了广泛应用。谷歌的TPU集群便是一个典型的例子,虽然单片TPU v4芯片的性能略逊于英伟达的A100,但谷歌凭借Cloud TPU集群的强大合力,成功训练出了参数高达5400亿的PaLM模型。这充分证明了在人工智能等擅长并行处理的领域,集群计算的规模效应能够有效弥补单芯片性能上的不足。
除了集群计算外,华为在算法优化方面也取得了显著成果。任正非提出的“用数学补物理”理念,在华为的技术实践中得到了充分体现。通过采用稀疏计算、模型量化和剪枝等前沿技术手段,华为降低了对硬件性能的依赖程度。其MindSpore框架通过动态图优化和低精度计算,使得AI训练的计算需求降低了30%以上。这种软硬件协同优化的模式,使得华为在制程相对较低的情况下,依然能够实现高效的计算效果。
华为的技术优势在实际应用中得到了充分验证。在天津港的无人化码头,由数百块昇腾芯片组成的计算集群发挥了“超级大脑”的关键作用。这些芯片实时处理海量传感器数据,精准指挥无人驾驶集卡和智能吊机,不仅提升了效率,降低了能耗,还让码头工人从高强度的体力劳动中解放出来。
AMD的崛起历程为华为提供了有益的借鉴。在2000年代,AMD曾被英特尔压制,但AMD凭借其CEO Lisa Su带领团队采用的模块化设计(Chiplet)和高效互联技术,成功推出了Zen架构处理器,强调架构和生态而非单一制程。这一成功经验与华为聚焦5G基站和AI计算等特定场景,通过针对性优化使效率远超通用芯片的集群策略不谋而合。
Chiplet技术是任正非战略思想在工程实践中的生动体现。该技术通过架构革新和系统级优化,成功弥补了单芯片制程上的代际差距,实现了整体性能的实用化突破。Chiplet技术将复杂的大芯片拆解为多个功能明确的小芯粒,这些芯粒可根据功能需求采用不同工艺节点制造,并通过先进的封装技术集成在一起,从而在系统层面实现媲美甚至超越单一先进制程大芯片的性能和功能。
然而,Chiplet架构也面临着芯粒间高速、低功耗、高带宽互连的挑战。华为在高速SerDes、先进封装中的互连线设计、信号/电源完整性仿真以及低延迟高带宽的互连协议等方面投入巨大,通过复杂的算法优化数据传输路径、降低噪声干扰、提升能效比,最大程度克服了物理限制,确保多个芯粒能够像单一芯片一样高效协同工作。
华为在“系统级创新”方面的优势,不仅体现在Chiplet技术上,还贯穿于其整个技术体系。通过“非摩尔”的异构集成路径、“数学”驱动的互连与系统优化能力以及“群计算”的分布式架构,华为在芯片系统(SoIC/SiP)层面实现了功能、性能和能效的实用化甚至领先水平。这有力证明了在尖端科技竞争中,突破性的架构设计和系统工程能力完全能够成为弥补底层物理技术代差、实现弯道超车和差异化竞争的核心驱动力。
华为之所以能够取得如此显著的成果,离不开其对人才和教育的长期战略性投入。华为拥有约11.4万名研发人员,过去十年的研发投入超过1.2万亿元。其“天才少年”计划吸引了众多顶尖人才,通过全球顶尖高校合作以及内部高强度研发实战,华为汇聚并培养了一批精通稀疏计算理论与工程实践的顶尖人才。这些人才深入参与昇腾AI芯片的架构设计,确保了硬件原生高效支持稀疏特性,实现了算法创新与芯片设计的深度协同。
尽管华为在技术创新和人才培养方面取得了显著成果,但挑战依然存在。集群计算在能耗、成本以及通信瓶颈等方面仍有待突破。在对单线程性能要求极高的部分科学计算场景中,集群优势难以充分发挥。然而,随着华为在芯片制造、供应链稳定性和全球化布局上的持续精进,相信华为将在更广泛的领域与国际巨头展开更加激烈的竞争。