在AI界的一次悄然行动中,DeepSeek再次成为焦点。业界翘首以盼的R2模型尚未露面,DeepSeek却以一种低调而有力的方式更新了其R1版本。
这次,DeepSeek R1摇身一变成了DeepSeek-R1-0528,依旧延续了其开源的特性,并在节日前夕悄然发布。新版本在命名上延续了DeepSeek一贯的风格,只是在版本号后加上了日期,如同之前的DeepSeek-V3-0324一样。
尽管名字变化不大,但DeepSeek-R1-0528的升级却非同小可。特别是在复杂推理、前端开发以及降低幻觉等方面,新版本带来了显著的进步。这一升级不仅提升了模型的实用性,也让DeepSeek在AI领域中的地位更加稳固。
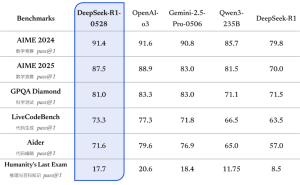
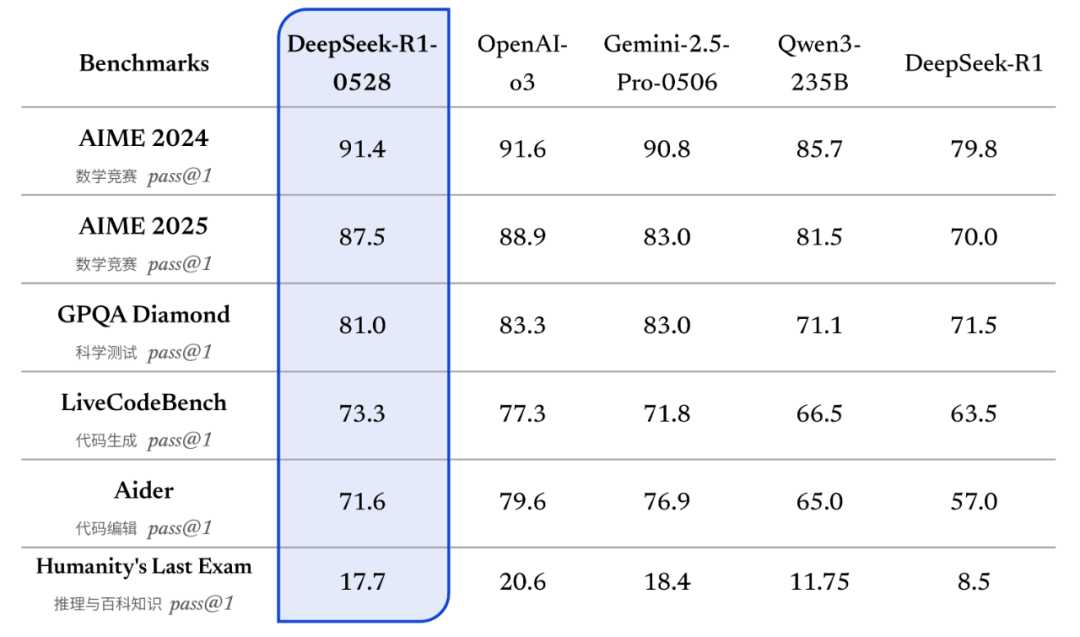
DeepSeek-R1-0528依旧采用了2024年12月发布的DeepSeek V3 Base模型作为基础,但这次它在后台投入了更多的算力。这使得模型能够像人一样进行更深入的思考,从而提供更准确的答案。例如,在AIME 2025测试中,旧版R1平均每题只需12K tokens即可完成,而新版R1-0528则需要23K tokens,足见其思考的深度和细致。
据网友实测,新版R1-0528在处理复杂问题时,能够连续思考25分钟之久。这种有意拉长的思考时长,无疑提升了模型的深度思考能力。在经典物理模拟测试中,DeepSeek-R1新旧版本的对比更是直观地展示了这一进步。
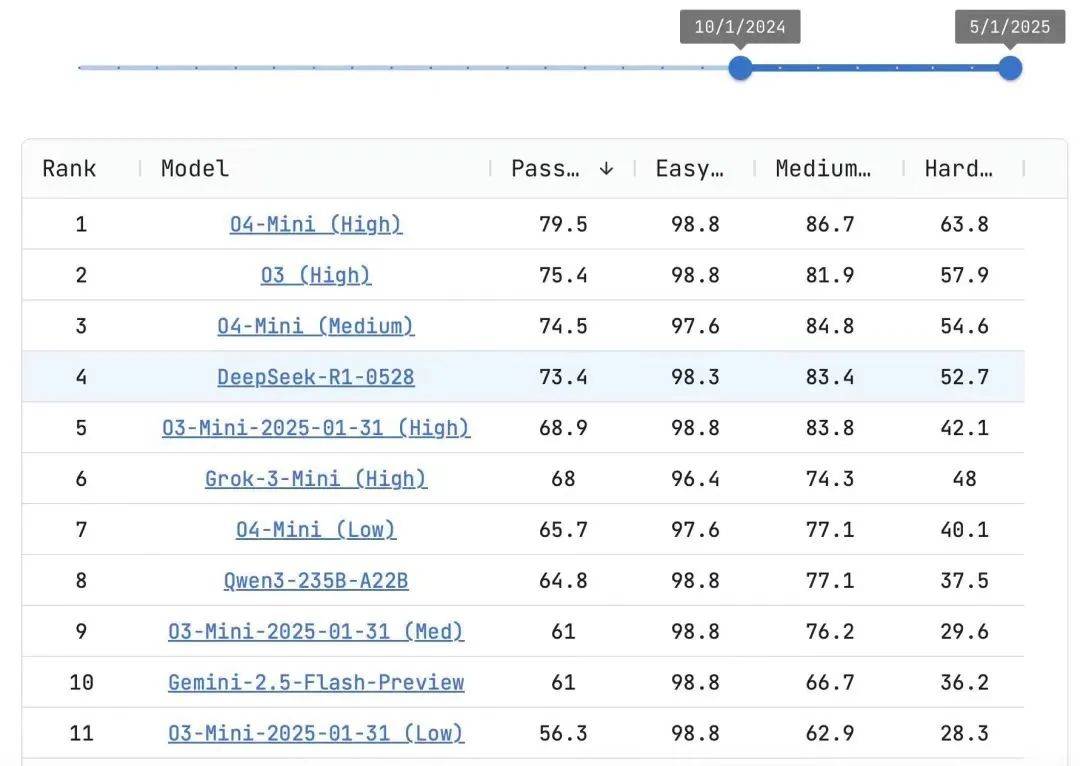
然而,这种长时间的思考是否值得,还需根据具体应用场景来判断。毕竟,一个问题花费半小时,即便结果再完美,也可能让用户感到焦急。但相应地,更深的思考带来了更强的编程和推理能力。在LiveCodeBench基准测试中,DeepSeek-R1-0528的成绩已经能够媲美o3-mini(High)和o4-mini(Medium),甚至在某些场景下超越了Gemini 2.5 Flash。
为了测试新版R1-0528在物理世界的推理能力,有网友用同一句提示让不同模型生成一个页面。结果显示,R1-0528一次性输出了728行代码,而Claude 4 Sonnet只给出了542行。经过仔细对比,新版R1-0528在细节处理上更加精致,无论是光影反射还是物体倒塌的模拟,都表现得更为出色。
在数学推理方面,DeepSeek-R1-0528也展现出了其强大的实力。不少网友提到,它是目前唯一一个能持续稳定地正确回答“9.9 - 9.11等于多少?”的模型。在构建单词评分系统时,新版R1-0528也仅用一次提示就生成了前后端文件,并成功运行,无需调试。

在语言对话方面,DeepSeek-R1-0528也进行了显著的优化。作为本土AI,它更贴合国内用户的需求,降低了幻觉率,使得输出内容更加靠谱。同时,在创意写作方面,新版R1-0528也表现出色,能够一气呵成地输出逻辑顺畅、情节自然的论文、小说和散文。

尽管DeepSeek-R1-0528的更新获得了不少好评,但也有一些网友对其持保留态度。他们认为这次更新“雷声大雨点小”,名不副实。然而,更多人还是对DeepSeek抱有期待,希望它能继续加强实力,真正成为“国产之光”。