在人工智能的发展历程中,经典模型的诞生往往预示着技术革命的新篇章。MoE模型,这一由加拿大学者于上世纪末提出的神经网络结构,便是在AI探索的初期阶段,播下了变革的种子。
时光荏苒,近十年前,硅谷的科技巨头们在理论与工程上实现了对MoE模型的突破,将这一学术理念推向了商业应用的舞台,点燃了AI竞争的火花。而今,这股创新的浪潮已跨越太平洋,来到了中国。以华为为代表的中国科技企业,正引领着MoE架构的新一轮优化与重组。
尤其是华为的MoGE架构,不仅解决了MoE模型中的负载不均衡与效率瓶颈问题,还实现了降本增效,极大地简化了模型的训练与部署流程。这一系列成就,再次彰显了东方智慧在科技领域的独特魅力。
近期,虎嗅推出了《华为技术披露集》系列内容,通过一系列技术报告,全面披露了华为在AI领域的最新技术细节。其中,华为通过“昇腾+Pangu Ultra MoE”的组合,实现了国产算力与国产模型的全流程自主可控训练闭环,且在集群训练系统性能上达到了行业领先水平。
在预训练阶段,昇腾Atlas 800T A2万卡集群的MFU(模型算力利用率)提升了41%;在后训练阶段,单CloudMatrix 384超节点的吞吐能力达到了35K Tokens/s。这一成绩的背后,是华为在技术创新上的不懈追求。
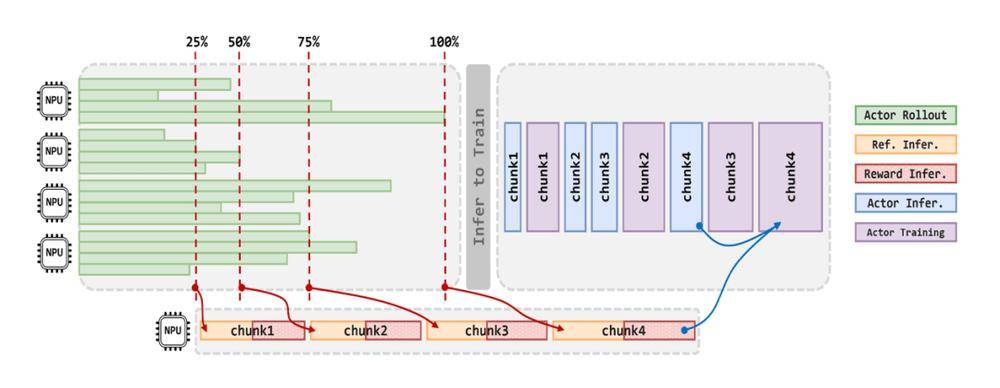
华为在技术报告中首次披露了高效打通大稀疏比MoE强化学习后训练框架的关键技术。这一技术的突破,使得以强化学习为核心的后训练进入了超节点集群时代。在深入探讨Pangu Ultra MoE训练系统之前,我们先来了解一下当前MoE预训练和强化学习后训练所面临的挑战。
这些挑战主要包括并行策略配置困难、All-to-All通信瓶颈、系统负载分布不均、算子调度开销过大、训练流程管理复杂以及大规模扩展受限等。面对这些挑战,华为给出了一套完整的端到端全流程解决方案。
首先,华为通过并行策略智能选择、计算通信深度融合以及全局动态负载平衡等技术,显著提升了训练集群的利用率。华为团队利用系统建模仿真框架,将并行策略选择问题转化为自动化搜索过程,为Pangu Ultra MoE 718B模型确定了最优部署配置。

训练系统建模仿真流程
其次,华为通过Adaptive Pipe前反向通算掩盖、昇腾亲和的训练算子加速以及Host-Device协同的算子下发优化等技术手段,成功释放了昇腾单节点的算力。这些优化措施不仅提升了关键算子的执行效率,还降低了Host资源的瓶颈,实现了微批处理规模的两倍提升。
最后,华为针对强化学习训练中异构模型和多任务场景导致的资源利用率偏低问题,提出了RL Fusion训推共卡技术。这一技术支持多种灵活部署模式,实现了推理阶段资源调度的精细化可控管理,并支持多维并行策略的动态无缝切换。
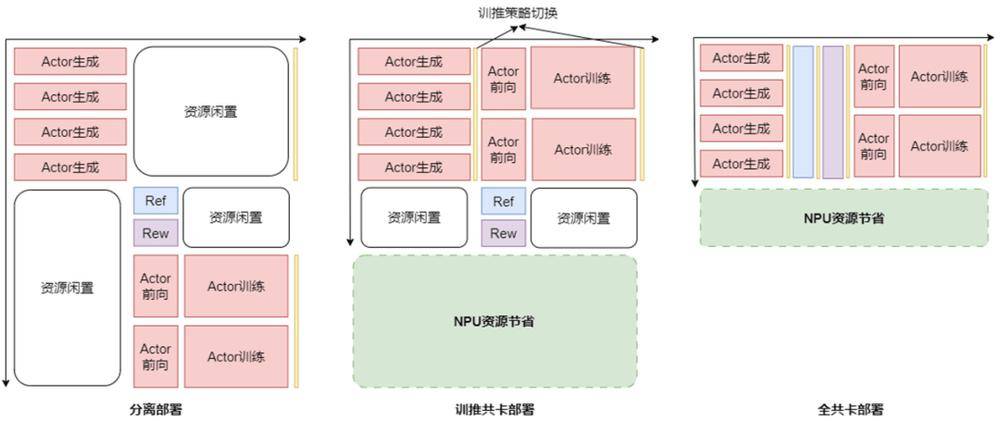
分离部署、训推共卡部署、全共卡部署资源利用率示意图
通过这一系列技术创新,华为打造了基于MindSpeed、Megatron以及vLLM框架的昇腾全流程高效训练系统。该系统可支持超大规模集群和超大规模MoE模型,并在Pangu Ultra MoE模型训练中实现了端到端的流畅训练。在预训练阶段,华为团队使用昇腾800T A2集群对Pangu Ultra MoE进行训练,模型算力利用率达到了41%。而在RL后训练阶段,每超节点的吞吐能力达到了35K Tokens/s,相当于每2秒就能解决一道高等数学大题。
这一成就不仅展示了华为在AI领域的深厚底蕴,也为中国乃至全球的AI发展注入了新的活力。随着技术的不断进步和应用的不断深化,我们有理由相信,AI的未来将更加美好。