
近日,字节跳动公司发布了其最新的技术报告,详细介绍了Seed1.5-Thinking模型。该报告英文版共计19页,深入探讨了这款混合专家模型(MoE)的技术细节与性能表现。
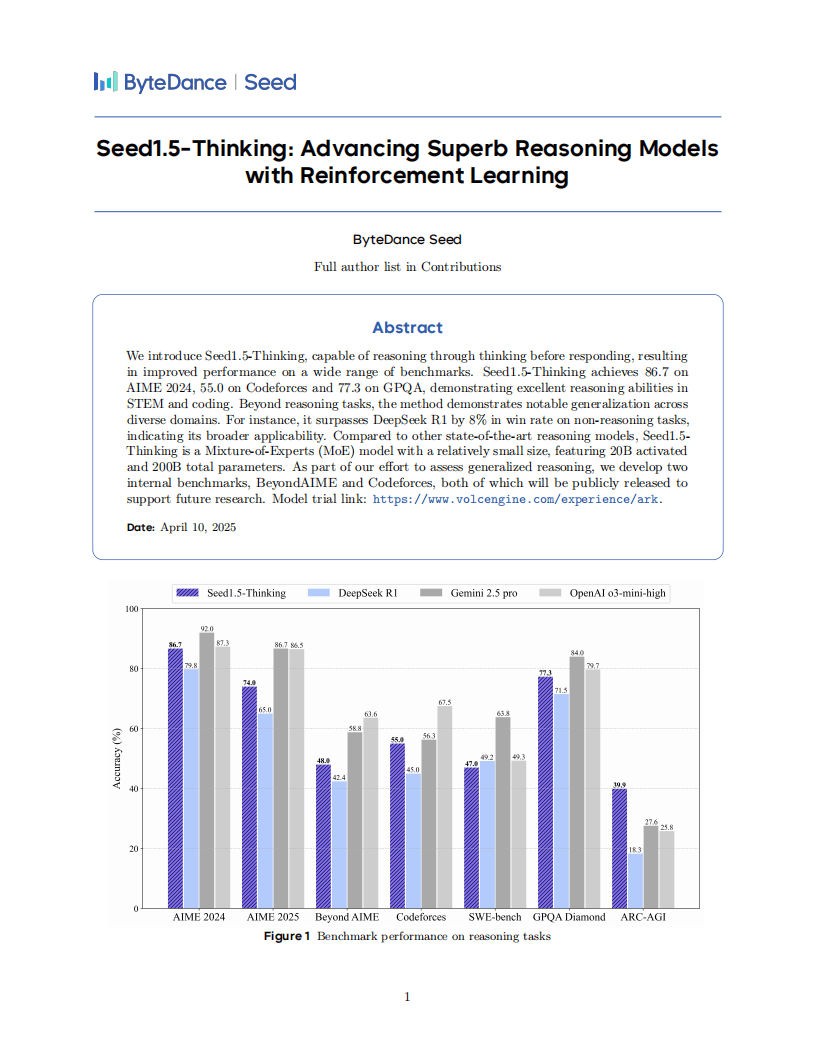
Seed1.5-Thinking模型以其强大的推理能力脱颖而出,拥有200亿的激活参数和总计2000亿的参数规模。在多项基准测试中,该模型均取得了优异成绩。例如,在AIME 2024竞赛中获得了86.7分,Codeforces比赛中取得55.0分,GPQA测试中达到77.3分。这些成绩不仅彰显了模型在STEM和编程领域的卓越实力,还展示了其在非推理任务上的广泛适用性,相较于DeepSeek R1模型,胜率提高了8%。
在模型开发过程中,数据、强化学习(RL)算法及RL基础设施被视为三大核心要素。数据方面,监督微调(SFT)主要依赖于链式思维(CoT)数据。报告指出,过多的非CoT数据可能会削弱模型的探索能力。RL训练数据则涵盖了STEM问题、代码任务等多个类别,其中数学数据的强大泛化能力有助于提升模型在各项任务中的整体性能。
针对RL算法训练中的不稳定性问题,字节跳动团队自主研发了VAPO和DAPO框架。这两个框架分别针对演员-评论家及策略梯度范式,有效解决了训练过程中的不稳定性,确保了训练的稳健进行。

在RL基础设施方面,混合引擎架构的采用大大提升了训练效率与可扩展性。Streaming Rollout System(SRS)能够缓解长响应生成中的滞后问题,结合多种并行机制和内存优化策略,进一步提升了训练效果。
评估结果显示,Seed1.5-Thinking在数学推理领域与OpenAI的o3-mini-high模型表现相当,但在AIME 2025和BeyondAIME等更高级别的测试中仍存在一定差距。在科学领域的GPQA测试中,该模型接近o3水平;在编程方面则接近Gemini 2.5 Pro的性能。特别在逻辑推理的ARC-AGI测试中,Seed1.5-Thinking展现出了突出表现。人类评估显示,该模型在非推理场景的整体胜率超过DeepSeek R1达8.0%,且更符合人类偏好。



字节跳动的这一技术突破不仅展示了其在人工智能领域的深厚积累,也为未来模型性能的进一步提升奠定了坚实基础。












