百度近日宣布了一项重大举措,正式开源了其文心大模型4.5系列,这一动作标志着百度在大模型领域的开放态度和技术实力的展现。
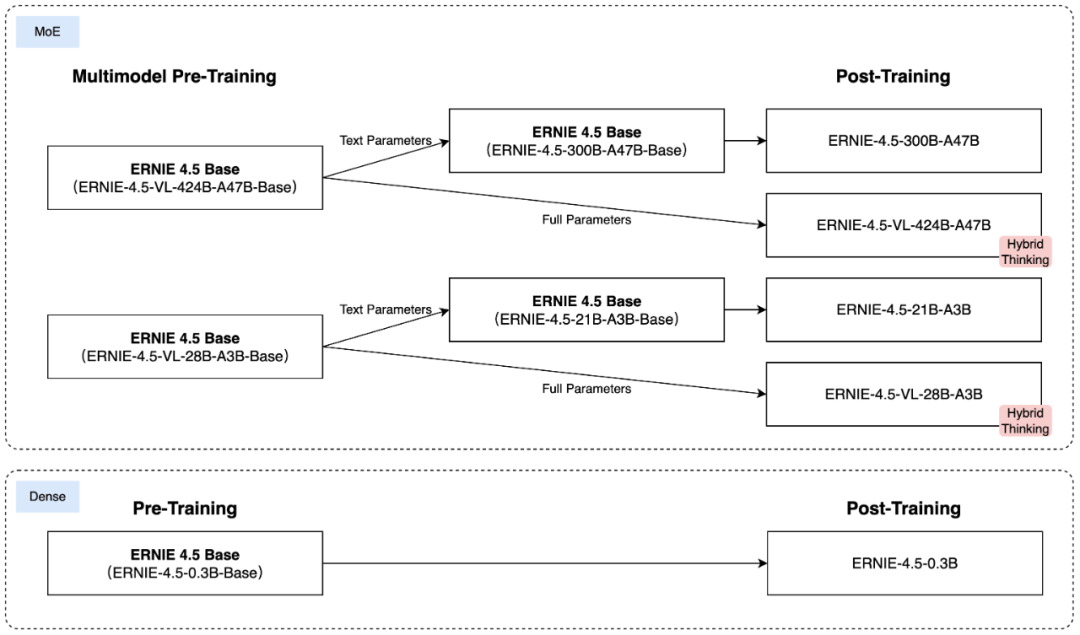
此次开源的模型涵盖了多个版本,包括拥有47B和3B激活参数的混合专家(MoE)模型,以及参数量为0.3B的稠密型模型。百度不仅开放了预训练权重,还提供了推理代码,确保开发者能够全面利用这些模型。
文心大模型4.5系列现已在飞桨星河社区、Hugging Face等多个平台上架,开发者可以轻松下载并部署。同时,百度智能云千帆大模型平台也提供了相应的开源模型API服务,进一步降低了开发门槛。
值得注意的是,百度此次并未开源其升级版文心大模型4.5 Turbo系列,但这并未影响开发者对文心大模型4.5系列的热情。在Reddit等开发者社区,不少用户表示,百度此次开源的模型在内存受限的配置下表现出色,尤其是28B模型在基础文本能力上增加的视觉功能,令人印象深刻。
文心大模型4.5自今年3月发布以来,便以其卓越的性能吸引了广泛关注。作为百度自研的新一代原生多模态基础大模型,文心大模型4.5在多个测试集上的表现已经超越了GPT-4。其图片理解能力尤为突出,能够涵盖多种形态的图片,包括照片、电影截图、网络梗图等,同时在生成名人、物品等方面也更具真实性。
文心大模型4.5系列的成功背后,是百度在技术创新上的不懈努力。该系列模型采用了多模态异构MoE预训练技术,通过联合训练文本和视觉模态,捕捉多模态信息的细微差别,提升了文本理解与生成、图像理解以及跨模态推理等任务的性能。百度还提出了异构混合并行和分层负载均衡策略,实现了模型的高效训练。在推理方面,多专家并行协作方法和卷积码量化算法的应用,使得模型在保持高性能的同时,实现了更低的资源消耗。