在人工智能的探索历程中,一个经典模型架构——混合专家(MoE)模型,自加拿大学者提出以来,已经走过了三分之一个世纪。这个在AI“石器时代”点燃变革火种的架构,近年来在美国硅谷的科技巨头手中,实现了理论与工程上的突破,成为AI竞争的重要推手。
而今,这股创新浪潮已跨越太平洋,来到中国。以华为为代表的中国科技企业,正积极优化重组MoE架构,其中华为的MoGE架构尤为引人注目。它不仅解决了MoE架构中的负载不均衡和效率瓶颈问题,还通过降本增效,使模型训练和部署更为便捷。
近期,虎嗅推出《华为技术披露集》系列内容,深度揭秘华为在MoE架构优化上的技术细节。该系列以技术报告的形式,全面展示了华为在AI领域的研究成果。
随着大模型的快速发展,MoE模型凭借其独特的架构优势,成为扩展模型能力的重要方向。MoE模型通过创新的路由机制,动态分配输入token给不同的专家网络,实现了模型参数的规模化扩展,并在处理复杂任务时展现出显著优势。然而,在分布式集群环境下训练MoE模型时,训练效率低下成为亟待解决的难题。
MoE模型训练集群的效率挑战主要体现在两方面:一是专家并行引入的计算和通信等待,导致大量计算单元空闲;二是负载不均导致的计算和计算等待,使得部分专家被频繁调用,而其他专家使用率较低。这种情况就像城市交通中的拥塞现象,计算和通信相互阻碍,降低了整体效率。
为了解决这些问题,华为团队提出了Adaptive Pipe & EDPB优化方案。这个方案就像一个“智慧交通枢纽”,使MoE训练集群实现无等待的流畅运行。其中,AutoDeploy仿真平台通过高精度建模和全局化算法加速运行,能在短时间内模拟百万次训练场景,找到与集群硬件规格匹配的最优并行策略。
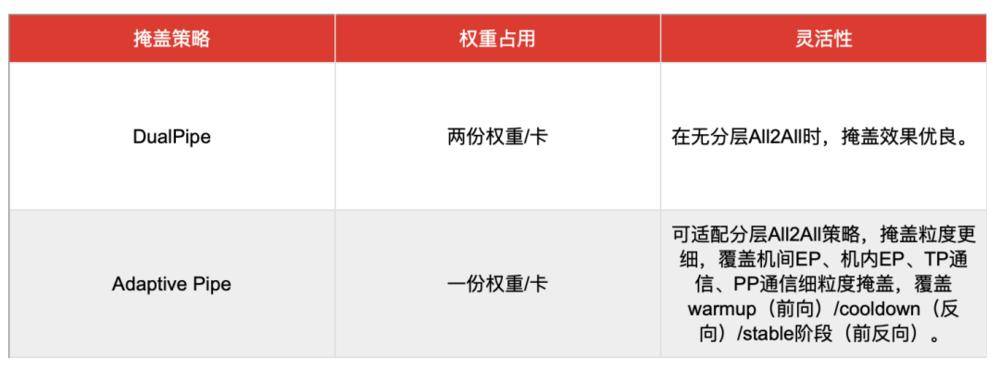
在此基础上,Adaptive Pipe通信掩盖框架实现了98%以上的EP通信掩盖,让计算引擎不受通信等待的束缚。它采用层次化All-to-All降低机间通信,并利用自适应细粒度前反向掩盖技术,实现通信几乎“零暴露”。这种优化策略显著提升了训练效率。
EDPB全局负载均衡技术通过专家预测动态迁移和数据重排Attention计算均衡等手段,实现了专家均衡调度,进一步提升了训练效率。在Pangu Ultra MoE 718B模型的训练实践中,华为团队在8K序列上测试了Adaptive Pipe & EDPB的吞吐收益情况,实现了系统端到端72.6%的训练吞吐提升。
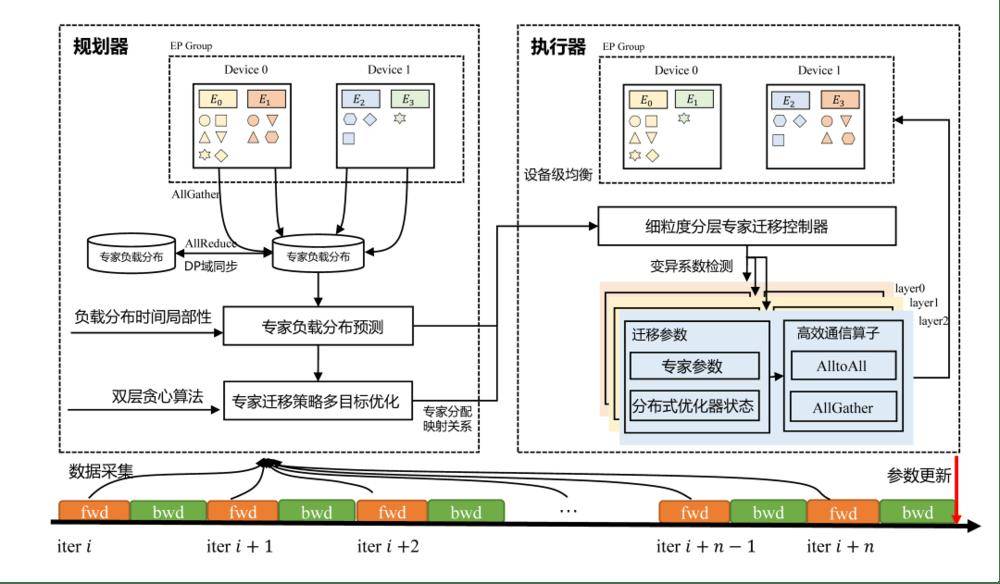
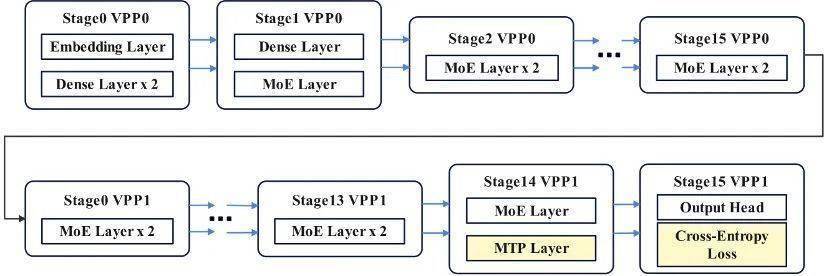
华为的技术创新不仅提升了MoE模型的训练效率,也为AI领域的发展注入了新的活力。随着《华为技术披露集》系列内容的发布,更多技术细节得以公开,相信这将为业界提供宝贵的参考和借鉴。