在人工智能技术迅速渗透各行各业的当下,大型模型的崛起正引领算力需求迈入一个全新的阶段。随着模型参数量的急剧增长,尽管传统集群架构可以通过不断扩展来满足算力需求,但集群间的通信效率却成为了制约大模型训练速度的关键因素。
一方面,各行各业对AI算力的需求持续攀升;另一方面,算力供应端却面临着通信延迟导致的效率瓶颈以及高昂的模型训练成本。这一矛盾愈发凸显,亟待解决。
传统集群架构的困境:从“简单堆砌”到“效率革新”的必然转变
回顾AI计算的发展历程,传统集群架构的局限性逐渐显现。由独立服务器通过以太网连接的系统,在处理如混合专家模型(MoE)等新型大型模型时,暴露出了三大主要问题:
首要问题是通信瓶颈的急剧恶化。MoE模型将任务分解为数百个专家并行处理,导致节点间的通信量大幅增加。传统的400G网络在面对TB级数据传输需求时,时延高达2毫秒以上,严重制约了训练效率。
其次是资源分配的不合理性。传统架构无法根据模型层间的计算特征进行动态调整,只能进行静态资源划分。这导致在MoE模型中,不同层的专家数量变化时,部分节点会出现过载或闲置的情况,整体训练效率下降超过30%。
最后是系统可靠性的不足。大规模集群中单个节点发生故障的概率随规模增大而线性增长,但传统系统的故障恢复需要数小时,期间所有训练数据需重新计算,造成了巨大的资源浪费。
这些痛点实质上反映了“以服务器为中心”的传统架构已无法适应大模型时代“以数据流动为核心”的算力需求。正如华为昇腾计算业务总裁所言:“当模型参数达到千亿级别时,算力架构必须从‘积木式堆叠’转变为‘有机生命体’。”昇腾超节点的出现,正是对这一挑战的积极回应。
超节点架构:重塑算力系统的“基因”
昇腾超节点的技术突破体现在对算力架构的底层重构上,其核心创新可概括为“三维一体”的技术架构:
在硬件互联方面,昇腾超节点通过高速总线连接多颗NPU,突破了互联瓶颈,使集群能够像一台计算机一样高效工作。跨节点通信带宽提升了15倍,通信时延降低至0.2毫秒,仅为原来的十分之一。
在全局内存管理方面,昇腾超节点采用虚拟化技术,将各节点的内存池虚拟为统一地址空间,支持跨节点直接内存访问。这大大简化了大模型训练中频繁的参数同步操作,提高了专家网络小包数据传输及离散随机访存的通信效率。
在资源调度方面,昇腾超节点能够深度感知MoE模型结构,实现细粒度动态切分。通过将模型层间的计算任务按专家分布动态分配到不同节点,并结合智能路由算法优化跨节点通信路径,使得计算与通信耗时比大幅提升。
在系统可靠性方面,昇腾超节点采用七平面链路设计、链路故障秒级切换以及算子级重传等可靠性技术,确保大模型训练不中断。同时,支持更敏捷的断点续训,故障恢复时长大幅缩短。
技术落地的“实践智慧”:从实验室到产业界的跨越
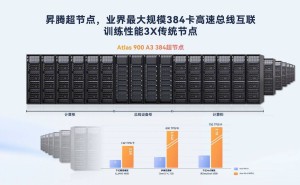
昇腾超节点架构以颠覆性创新打破了集群互联的瓶颈,通过技术革新实现了节点间的高效协同,使集群运行如同一台强大的计算机,整体计算效率大幅提升。其构建的业界最大规模384卡高速总线互联体系,相比传统节点,训练性能实现了3倍飞跃。
同时,昇腾超节点架构深度适配MoE模型,充分释放了其潜力,为模型训练与推理提供了高效支持。这使得昇腾成为MoE模型开发与应用的最优选择,在AI计算领域树立了新的标杆。
全新发布的MindIE Motor在推理服务层进行了加速,进一步提升了大规模专家并行的能力。其单卡吞吐达到传统服务器堆叠的4倍,超节点与大EP方案性能更是达到业界的4倍,有效保护了客户的投资。
昇腾还推出了多模态理解SDK和昇腾推理微服务MIS,大幅简化了应用的部署流程,让开发者能够更加专注于应用的创新。
昇腾超节点的价值不仅在于其技术创新的前瞻性,更在于其产业落地的扎实努力。华为通过“三位一体”的实干策略,实现了从架构创新到生态繁荣的闭环。
早在2022年,华为就与DeepSeek等头部AI企业建立了联合实验室,针对MoE模型特性对超节点架构进行优化。这种“需求驱动创新”的模式,确保了超节点始终紧贴产业前沿。
华为坚信“用架构创新释放摩尔定律”,正如其轮值董事长所言:“当制程工艺逼近物理极限时,架构创新就是新的摩尔定律。”在AI算力的竞技场上,昇腾选择了一条艰难却坚实的道路,攻克了高速互联、动态调度、系统可靠性等世界级难题,为AI产业的繁荣发展奠定了坚实基础。