近日,字节跳动旗下的Seed团队在人工智能领域迈出了重要一步,正式向公众开源了其精心打造的Seed-OSS系列模型。这一系列模型专为处理长上下文、推理任务、Agent行为及通用场景而设计,其上下文窗口的扩展能力尤为引人注目,达到了惊人的512k,是业界常规窗口大小的四倍,甚至超越了GPT-5的两倍,相当于能够一次性涵盖约1600页文本的信息量。
Seed-OSS系列模型在推理能力上进行了深度优化,并且为用户提供了前所未有的灵活性,允许他们根据实际需求调整所谓的“思维预算”。这一功能对于控制模型推理成本、优化使用体验具有重要意义。Seed团队此次共推出了三个版本的模型,包括基础版Seed-OSS-36B-Base、无合成数据基础版Seed-OSS-36B-Base-woSyn,以及经过指令微调的Seed-OSS-36B-Instruct。
在通用知识、Agent行为、编程及长上下文等多个领域的基准测试中,指令微调后的Seed-OSS-36B-Instruct表现尤为突出,取得了同量级开源模型中的七项最佳性能(SOTA)记录。其整体能力超越了Qwen3-32B、Gemma3-27B、gpt-oss-20B等模型,与Qwen3-30B-A3B-Thinking-2507在多个领域并驾齐驱。这一成就不仅彰显了Seed团队的技术实力,也为开源社区带来了新的研究方向和可能性。
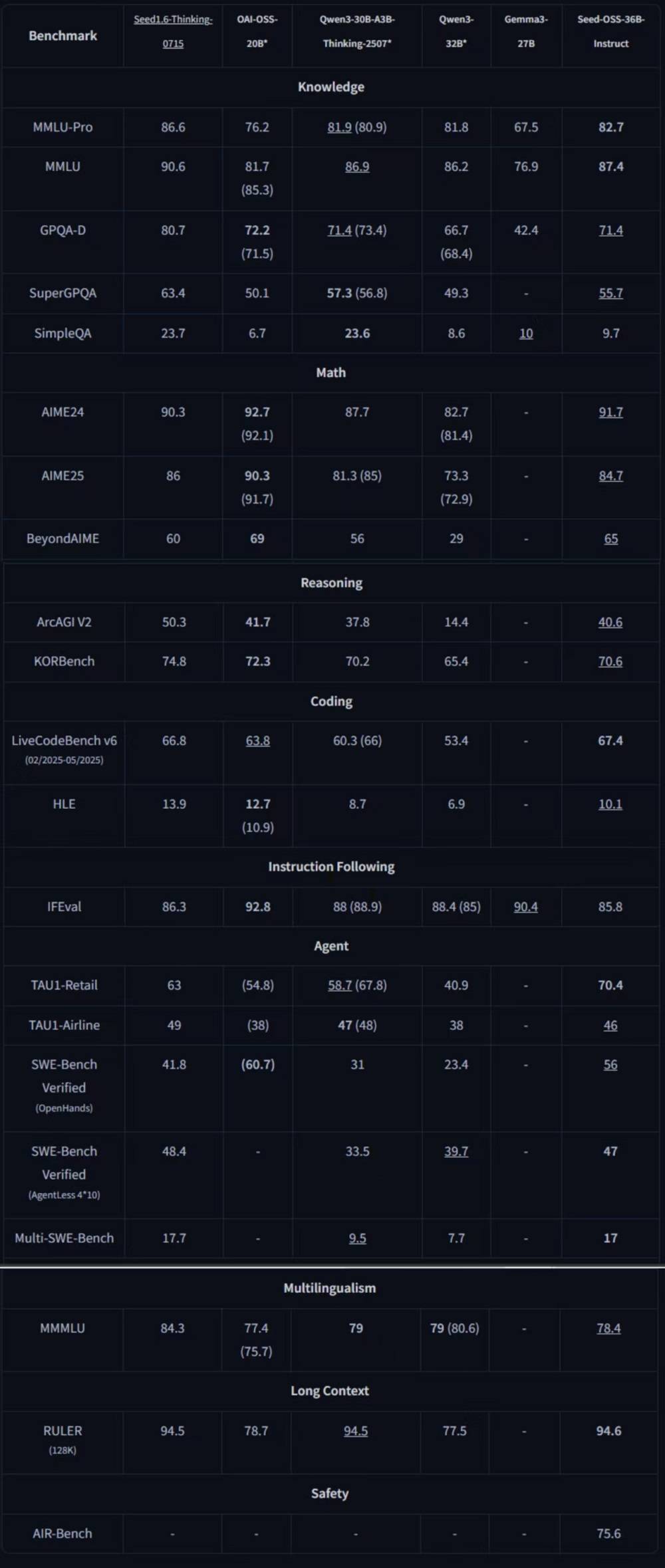
▲基准测试结果,加粗项为开源SOTA
Seed团队在发布这一系列模型时,充分考虑了研究社区的需求。他们意识到,预训练中包含的合成指令数据可能会对后续的研究产生影响,因此特意发布了无合成数据基础版模型,为研究者提供了更多样化的选择。这一系列模型还支持4位和8位格式的量化,以进一步减少内存需求,提高模型的实用性。
Seed-OSS系列模型采用了宽松的Apache2.0开源协议,这意味着任何人都可以自由地使用、修改和分发这些模型。同时,Seed团队还计划在未来发布模型的详细技术报告,以便更多人了解其背后的技术原理和实现细节。这一举措无疑将推动人工智能领域的进一步发展和创新。

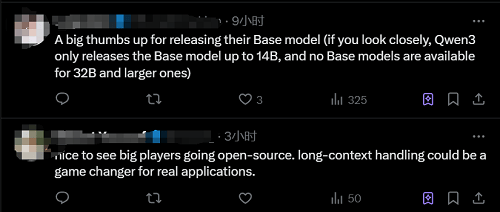
自发布以来,Seed-OSS系列模型已经获得了不少开发者的认可和好评。Hugging Face的华人工程师Tiezhen Wang评价道,这一系列模型非常适合进行消融研究,能够以较低的成本探索不同组件对大模型性能的影响。还有网友指出,这种尺寸的基础模型在开源界中较为罕见,而长上下文能力对于实际应用而言具有极大的价值。
近年来,开源已经成为人工智能领域的重要趋势之一。越来越多的企业和研究机构开始将他们的模型和技术开源,以促进技术的共享和进步。字节跳动此次将Seed-OSS系列模型贡献给社区,无疑为开源社区的后续研究提供了更多基础模型的选择和参考。这一系列模型的发布,不仅展示了字节跳动在人工智能领域的技术实力和创新精神,也为整个行业的发展注入了新的活力和动力。