苹果最新论文在AI领域引发轩然大波,质疑大模型推理能力真实性。
近日,苹果公司发布的一篇关于大模型推理能力的论文,在人工智能圈内掀起了巨大波澜。该论文直言不讳地指出,当前主流的大模型,包括DeepSeek、o3-mini以及Claude 3.7等,虽然在表面上展现出强大的推理能力,但实际上只是在进行“模式匹配”,所谓的“思考”不过是假象。

论文作者团队中,不乏业界重量级人物,如谷歌大脑创始人之一的Samy Bengio。他们指出,在面对高度复杂的任务时,这些大模型无一例外都会陷入困境,即便给予它们充足的时间和计算资源,也无法扭转颓势。
这一观点迅速在网络上发酵,引发了广泛讨论。有网友讽刺苹果,坐拥巨额资金却两年来未能拿出令人信服的成果,如今落后了便开始否定他人的努力。也有人建议苹果直接收购Claude背后的公司Anthropic,以免错失良机。
然而,也有声音认为这篇论文并非全然悲观。它实际上是在呼吁业界建立更为完善的推理机制和评估体系,以更客观地衡量大模型的推理能力。那么,这篇论文究竟提出了哪些新见解呢?
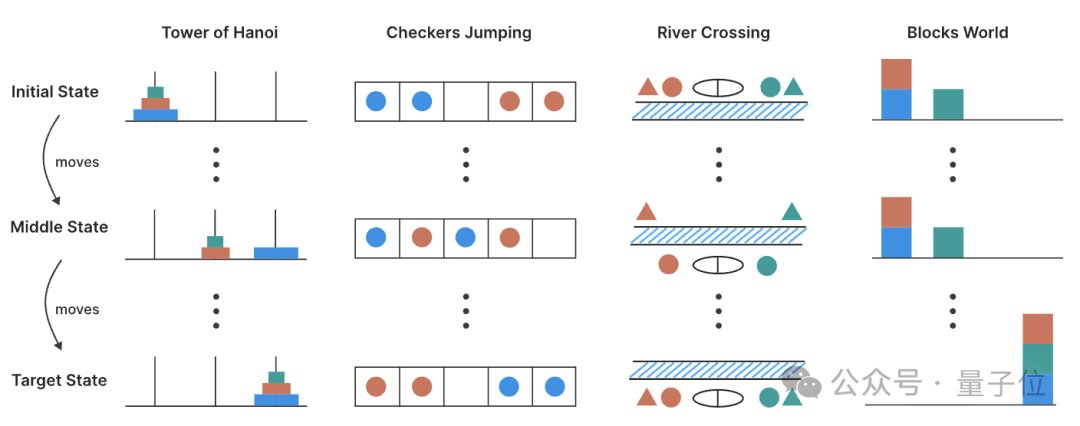
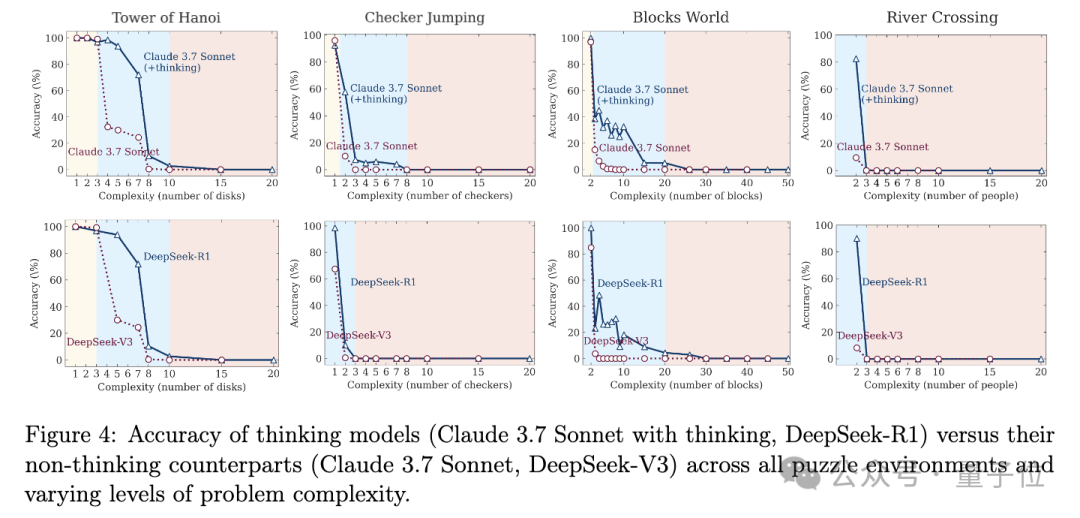
论文指出,当前对大模型推理能力的评估主要依赖于既定的数学和编码基准,这种评估方式可能存在数据污染的问题,且缺乏对“思考过程质量”的深入分析。为了克服这些限制,苹果团队设计了四类谜题环境,包括汉诺塔、跳棋交换、过河问题和积木世界,这些谜题环境的难度可以精确控制,便于系统观察模型在不同复杂度下的行为变化。
通过大量实验,苹果团队发现,随着任务复杂度的增加,模型的表现呈现出截然不同的三个阶段。在低复杂度任务中,没有“思考”功能的标准语言模型反而表现更佳,既准确又高效。随着任务难度进入中等水平,能够生成长思维链的推理模型开始显现优势。然而,当问题复杂度继续增加并超过某个临界点时,无论是推理模型还是标准模型都会遭遇性能崩溃,准确率直线下降至零。
更令人惊讶的是,苹果团队观察到了“推理努力反向缩放”现象。在任务复杂度提升后,模型一开始会随着问题变难而加大思考量,但接近崩溃临界阈值时,却会反直觉地开始“主动减少思考”,即使计算资源还远未耗尽。这表明模型本身存在某种内在的计算扩展限制。

苹果团队还针对Claude-3.7-Sonnet (thinking)模型进行了深入分析,发现模型在处理简单问题时往往会“过度思考”,浪费计算资源;而在处理更复杂问题时,则无法生成任何正确的解决方案。这一发现进一步凸显了推理模型在验证和遵循逻辑步骤解决问题方面的局限性。
论文的发表,无疑给当前如火如荼的大模型研究泼了一盆冷水。然而,正如有人所言,苹果在大模型上的进展虽然不尽人意,但其提出的问题和挑战却值得业界深思。未来如何设计更鲁棒的推理机制,突破长程依赖和复杂规划的瓶颈,将是AI研究的关键方向。