近期,关于Agent(智能体)技术发展的讨论热度不减。本文旨在深入探讨当前Agent技术的最新进展及其在不同领域的应用现状。
在定义与核心争议方面,Agent尚未形成一个统一且明确的定义。学界与业界对此存在分歧,焦点在于是否应将“自主规划能力”作为Agent的核心特征。学界,如李飞飞团队,倾向于认为Agent应具备包括环境感知、任务规划、记忆学习等在内的完整闭环能力。而业界则更注重结果导向,例如OpenAI将Agent定义为能独立完成任务的系统,强调其通过大型语言模型(LLM)管理工作流、调用工具及动态纠错的能力。Anthropic则进一步区分了Agent与Workflow,指出前者是由LLM自主编排流程,后者则依赖预定义代码路径协调工具。
技术驱动方面,Agent的核心能力依赖于大语言模型(LLM)和视觉语言模型(VLM)的深度集成。通过海量多模态数据的训练,大模型形成了强大的语义理解与环境交互能力,成为Agent的“认知基座”。Agent能力的提升遵循了一个从模仿学习到解耦、泛化,再到涌现自主决策能力的路径。目前,Agent已形成多种类别,包括跨领域交互的通用Agent、在物理环境中执行的具象Agent,以及能够动态创建内容的生成式Agent等,广泛应用于医疗、机器人、游戏等多个领域。

中美大厂在Agent布局上呈现出不同的策略。北美厂商以云服务为基础,聚焦于Agent的部署与平台化管理。例如,Google通过Vertex AI和Agentspace助力模型部署,推出A2A协议以降低多Agent通信损耗。Microsoft在Azure AI Foundry中集成了多模型,其办公场景Agent如Teams会议助手已显著提升用户效率。而国内厂商则延续互联网流量逻辑,同时推进B端平台化。如字节跳动的“扣子空间”接入了飞书生态,提供通用与专家Agent;百度“心响”APP以免费策略下沉C端市场,支持多达200种任务类型。

然而,Agent的落地也面临着诸多挑战。算力需求方面,Agent对算力的消耗显著高于传统AI产品,单次任务Token消耗可达十万级别。技术层面,Agent面临着意图混淆、多Agent协作效率及“幻觉”(生成错误信息)等问题。学界与业界正在通过不同方法进行优化,如贝叶斯实验设计、分层架构以及引入检索增强生成(RAG)技术等。

尽管存在挑战,但Agent技术仍在不断迭代与发展。随着A2A、MCP等协议的普及,跨Agent协作效率将得到提升。同时,多模态技术的突破将推动Agent在医疗、工业等领域的落地应用。例如,在医疗领域,结合知识库的Agent能够提升诊断准确性,减少“幻觉”问题的发生。

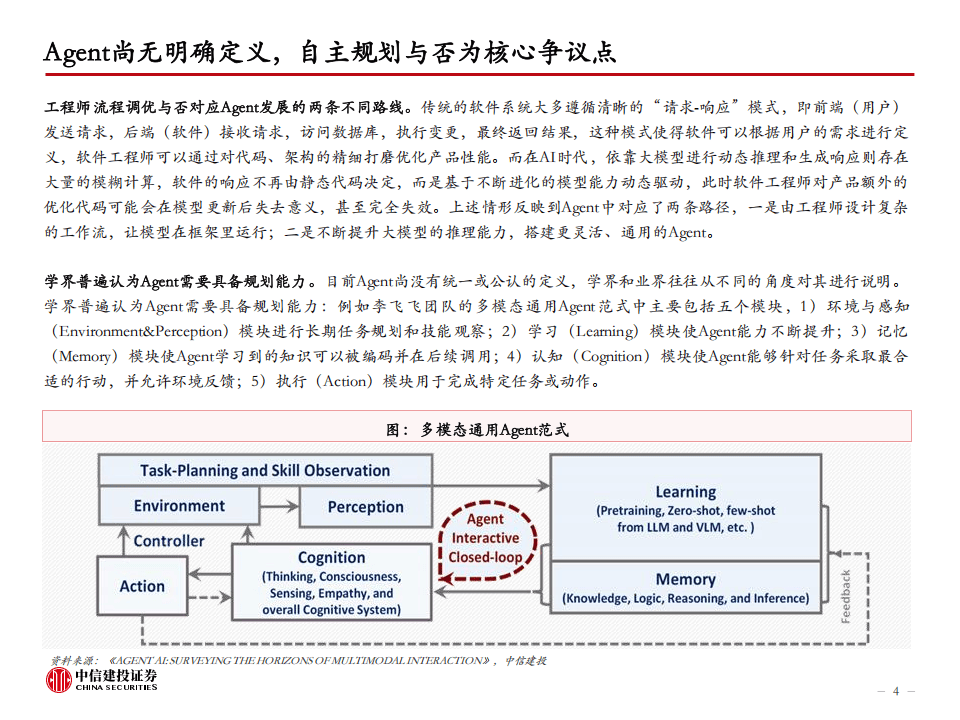
随着技术的不断进步和应用场景的拓展,Agent有望成为企业数字化转型的核心工具,推动AI产业链从模型层向应用层延伸。未来,具备数据、场景和平台能力的企业将在这一领域占据领先地位。