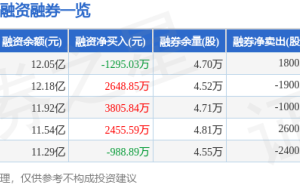
在人工智能领域,能够自主浏览网页并完成任务的智能体正成为研究热点。近日,Allen人工智能研究所(Ai2)推出了名为MolmoWeb的开源视觉网络智能体,这一成果为该领域带来了新的突破。作为Molmo 2模型家族的新成员,MolmoWeb以其独特的技术路径和开源特性引发了广泛关注。
MolmoWeb的最大亮点在于其开源属性。该模型提供了40亿和80亿参数两种版本,这种轻量化设计使其能够在本地设备上运行,大大降低了使用门槛。与市场上许多依赖专有技术的同类产品不同,Ai2团队选择了完全开放的道路,不仅公开了模型权重,还同步发布了训练数据、代码(即将上线)和评估工具,为研究人员提供了完整的研究框架。
在技术实现上,MolmoWeb采用了与众不同的训练方法。研究团队没有借助专有视觉智能体的知识蒸馏,而是通过两种途径构建训练数据:一是收集了30,000个人类操作轨迹,覆盖1,100多个网站的近600,000个子任务;二是利用可访问性树技术生成合成轨迹。这种组合方式既保证了数据的多样性,又解决了单纯依赖人工标注成本高昂的问题。训练数据中还包含了220多万个问答对,帮助模型理解网页内容。
实际性能测试显示,MolmoWeb在多个基准测试中表现优异。在浏览器操作任务中,它的表现超过了OpenAI的旧版GPT-4o模型,在开放权重模型中更是领先于Fara-7B和GLM-4.1V-9B等竞争对手。尽管与Anthropic、谷歌等公司的专有模型相比仍有差距,但MolmoWeb的开源特性使其成为研究社区的重要参考。
Ai2团队强调,他们的目标不是与商业巨头竞争,而是为学术界提供可复现的研究基础。当前网络智能体领域面临的一个关键问题是缺乏公开资源,这限制了研究的透明度和进展速度。MolmoWeb的发布,包括其庞大的训练数据集(包含带注释的网页截图和操作轨迹),为解决这一问题提供了重要资源。
目前,MolmoWeb的相关资源已在Hugging Face和GitHub平台开放下载。研究人员可以获取完整的模型架构、训练数据集以及评估工具包,这为深入理解网络智能体的工作原理和改进方向提供了宝贵机会。随着更多研究者基于这一开源框架开展工作,网络智能体技术有望迎来新的发展阶段。