近日,科技领域的一场小实验引发广泛关注——科技从业者路易斯在社交媒体上分享了关于大语言模型(LLM)在数学问题判断中的表现差异,该内容迅速被埃隆·马斯克转发,引发行业内外对人工智能逻辑能力的热议。
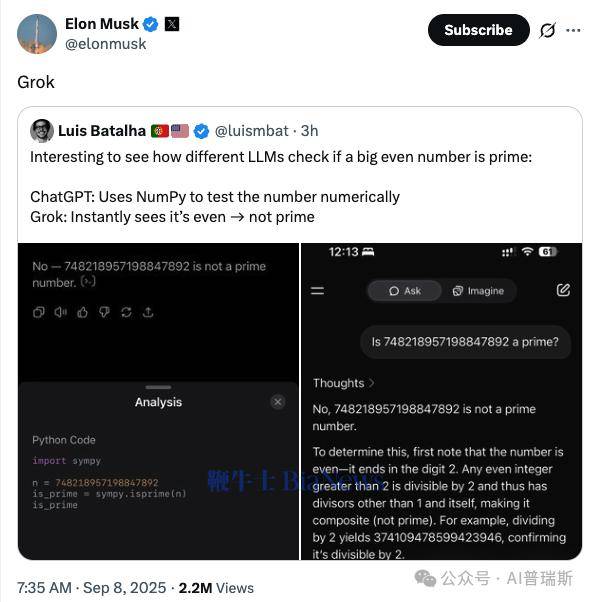
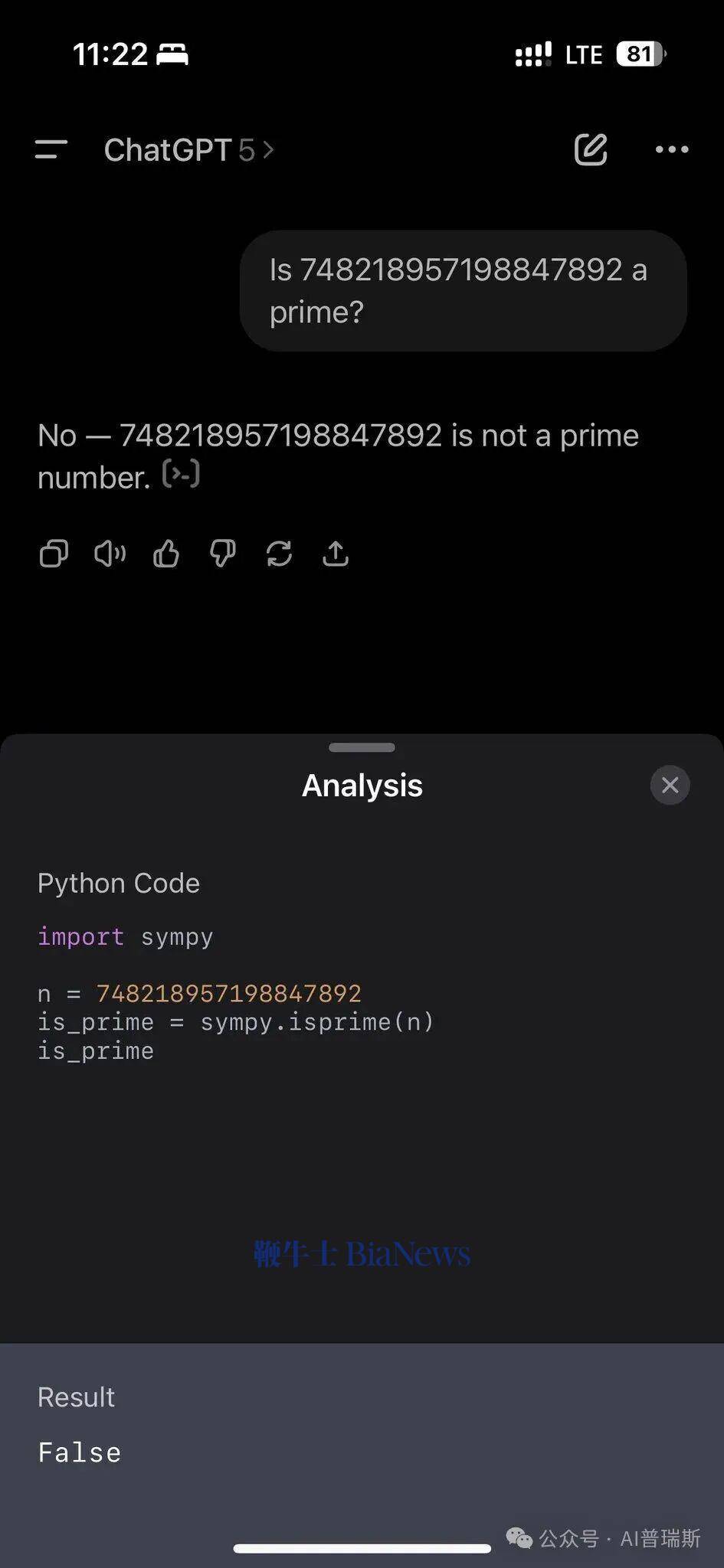
实验的核心问题聚焦于“大偶数是否为质数”的判断。以“748218957198847892是否为质数”为例,不同大语言模型给出了截然不同的处理方式。其中,ChatGPT选择了调用NumPy工具包进行数值计算,通过复杂的数学验证流程来确认结果。这种“数值化验证”模式体现了模型对计算严谨性的追求,试图通过外部工具确保结论的准确性。
相比之下,X平台旗下的Grok则展现了另一种思路。面对同样的问题,它直接调用了“除2以外,所有偶数都不是质数”这一基础数学常识,仅凭问题中的“偶数”特征便瞬间得出否定结论。这种“直觉式调用”的逻辑方式,跳过了复杂的数值计算,直接锁定问题的核心特征,实现了更高效的推理。
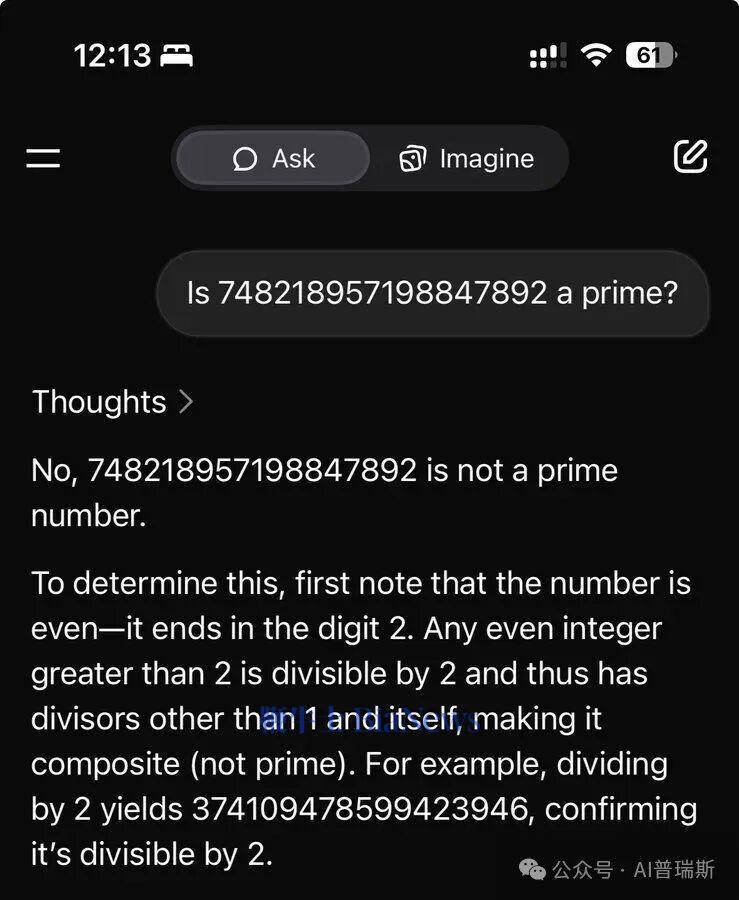
两种截然不同的处理方式,揭示了当前大语言模型在逻辑推理与工具使用上的设计差异。ChatGPT的路径更依赖外部工具的协作,通过数值验证确保结论的可靠性;而Grok则侧重于对基础知识的内化,利用数学常识快速解决问题。这种差异不仅体现在处理效率上,更反映了模型对问题本质的理解深度。
实验结果引发了行业内的深入讨论。专家指出,大模型的“常识储备深度”与“工具协作能力”是当前技术发展的两大关键方向。前者考验模型对基础知识的内化效率,即能否快速调用已有知识解决问题;后者则关乎模型与外部系统的协同智能,即能否通过工具扩展自身能力。如何在两者之间找到平衡,成为未来模型优化的重要课题。