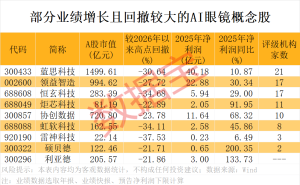
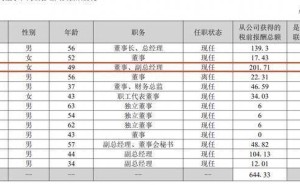
谷歌DeepMind近日宣布推出Gemini Embedding 2,这一原生多模态嵌入模型实现了文本、图像、视频、音频及文档五种媒体形式的统一嵌入,标志着人工智能嵌入技术进入全模态融合的新时代。该模型突破了传统嵌入模型仅支持单一模态的局限,通过将不同类型的数据映射至同一向量空间,为多模态应用开发提供了更高效的解决方案。
在技术架构上,Gemini Embedding 2基于Gemini框架构建,支持多种输入格式:文本处理能力提升至8192个token,图像可同时处理6张PNG或JPEG格式文件,视频支持最长120秒的MP4/MOV格式,音频可直接生成嵌入向量无需转录,文档则支持6页以内的PDF文件。该模型最显著的创新在于支持交错输入,允许开发者在单次请求中混合多种模态数据,从而捕捉不同媒体类型间的复杂语义关联。
性能表现方面,谷歌披露的基准测试数据显示,Gemini Embedding 2在文本、图像及视频任务中均超越当前主流模型。特别值得关注的是其原生语音处理能力,这项此前同类模型普遍缺失的功能,使音频数据可直接生成嵌入向量,省去了语音转文字的中间环节,显著提升了处理效率。为平衡性能与成本,模型延续了Matryoshka表示学习技术,允许开发者根据应用场景将输出维度从默认的3072灵活调整至1536或768。
对于企业用户而言,该模型的发布具有重要实践价值。通过统一嵌入空间的设计,开发者构建多模态检索增强生成(RAG)、语义搜索及数据分类系统的技术门槛大幅降低。以往需要分别处理不同模态数据的复杂管道,现在可通过单一模型简化实现。谷歌特别强调,维度压缩技术使大规模部署嵌入向量的企业能够在控制基础设施成本的同时,保持较高的模型精度。
目前,Gemini Embedding 2已通过Gemini API和Vertex AI平台开放预览,开发者可立即接入使用。据谷歌透露,部分早期合作伙伴已基于该模型开发出多模态应用,这些实践案例正在验证其在高价值场景中的实际效能。随着嵌入技术在上下文工程、大规模数据管理及传统搜索分析等领域的广泛应用,这款新模型有望推动相关技术生态的进一步发展。