
当科技圈还在热议谷歌即将发布的Gemini 3时,马斯克旗下的xAI公司已悄然抛出一枚重磅炸弹——全新大模型Grok 4.1系列正式上线。这款被寄予厚望的AI产品不仅在响应速度和事实准确性上实现突破,更以"双形态"策略在性能测试中力压群雄,成为2025年大模型竞赛中的一匹黑马。
此次发布的Grok 4.1系列包含标准版和Thinking增强版两大形态。后者作为推理特化型变体,通过引入"思考令牌"机制实现链式推理,在处理复杂数学、编程和多步骤问题时展现出显著优势。两个版本共享底层架构,仅在推理配置上存在差异,这种模块化设计既保证了基础性能的稳定性,又为专业场景提供了定制化解决方案。
在全球权威大模型评测平台LMArena的最新榜单中,Grok 4.1 Thinking以1483分的Elo评分登顶冠军,标准版也以1465分紧随其后。更令人瞩目的是,标准版在非推理模式下超越了所有竞争对手的推理模型,将前代产品Grok 4远远甩至第33名。这种"快模型"跻身顶级性能梯队的现象,标志着大模型发展进入新阶段。

性能跃升的背后是训练方法的革命性创新。xAI团队引入大规模强化学习系统,并采用前沿推理模型作为奖励机制,使模型具备自主评估和快速迭代能力。这种训练方式带来的直接效果是幻觉率从12.09%骤降至4.22%,在事实准确性测试FActScore中,错误率也显著降低。测试数据显示,新模型在处理检索类任务时,不再依赖语义猜测,而是能提供基于证据的可靠回答。
在情感智能领域,Grok 4.1同样交出亮眼成绩单。EQ-Bench情商测试中,该模型以1586分的成绩领跑榜单,较前代提升超过100分。通过45个角色扮演场景的深度测试,新模型展现出更细腻的情绪理解能力。例如在"安慰失去宠物"的场景中,模型能准确捕捉"空睡窝""期待喵叫"等细节,用自然流畅的语言传递共情,这种表现已接近人类水平。
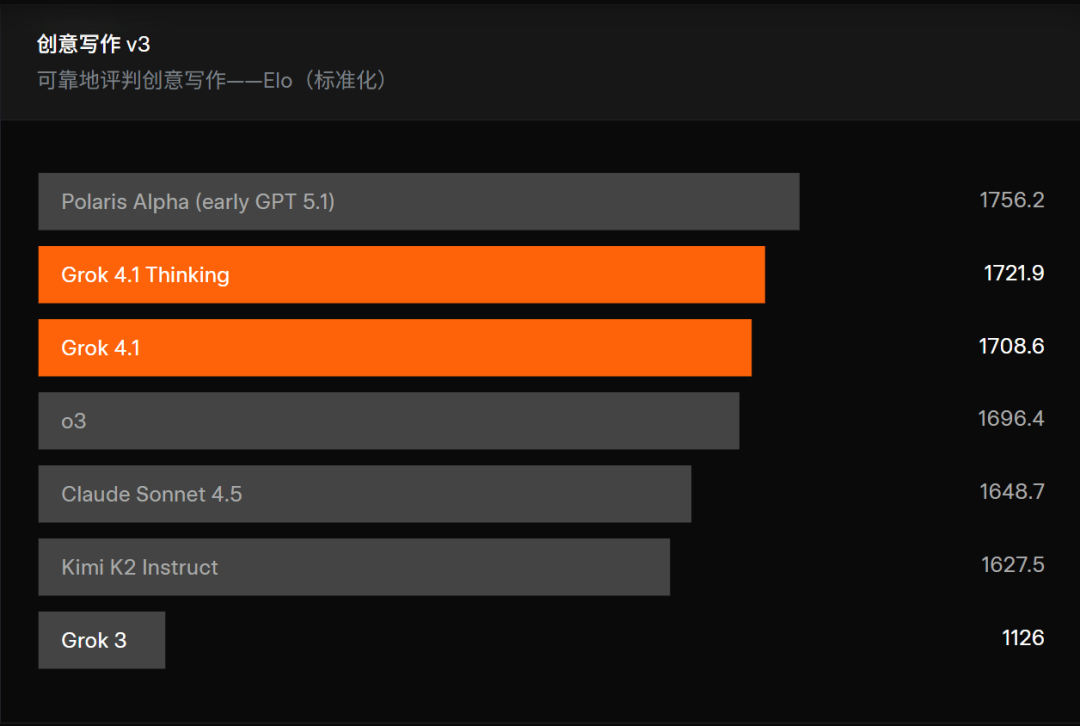
创意写作能力的突破同样引人注目。在Creative Writing v3基准测试中,Grok 4.1以1722分的成绩进入全球顶尖梯队。该测试要求模型完成32个类别的三轮独立创作,涵盖叙事构建、风格模仿等复杂任务。实测显示,新模型已从"段子手"进化为具备文学素养的创作者,其生成的旧金山旅游攻略不仅包含实用信息,还能传递城市气质,展现出独特的"人格魅力"。
技术突破的同时,xAI也注重用户体验的优化。Grok 4.1系列支持256K tokens的上下文窗口,Fast模式下更可扩展至200万tokens,这在长文档处理和持续协作场景中具有显著优势。更值得关注的是,该系列模型对所有用户免费开放,并同步推出iOS和安卓双平台应用,这种开放策略或将重塑大模型市场的竞争格局。
在正式发布前,Grok 4.1已进行为期两周的静默测试。数据显示,在双盲对比中,64.78%的用户更偏好新模型的回答。这种来自真实场景的验证,为模型性能提供了最有力的背书。从性能指标到用户体验,从技术突破到市场策略,Grok 4.1的全面升级不仅为xAI赢得竞争优势,也为整个行业树立了新的标杆。












