春节前夕,国内人工智能领域迎来新一轮技术竞赛,多家科技企业接连发布大模型升级成果,为行业注入新活力。2月14日,字节跳动正式推出豆包大模型2.0系列,针对真实场景中的复杂任务需求进行深度优化,引发市场广泛关注。该系列包含Pro旗舰版与Lite轻量版两个版本,在数学推理、多模态理解及成本控制等方面展现出显著优势。
在核心能力突破上,豆包2.0 Pro旗舰版交出亮眼成绩单:该模型在国际数学奥林匹克(IMO)、中国数学奥林匹克(CMO)及国际大学生程序设计竞赛(ICPC)模拟测试中均斩获金牌,在Putnam数学竞赛基准测试中超越Gemini 3 Pro,数学推理能力跻身全球顶尖行列。针对跨学科知识应用场景,模型通过强化长尾领域知识覆盖,在SuperGPQA科学知识测试中与Gemini 3 Pro、GPT 5.2持平,在跨领域问题解决中表现尤为突出。
多模态交互能力成为本次升级重点。豆包2.0全面升级视觉推理与空间感知模块,在权威测试中实现业界最佳表现,可精准解析图表、复杂文档及视频内容。动态场景处理方面,新增的时间序列分析模块支持实时视频流解析,已应用于健身动作纠正、穿搭智能推荐及老年人看护等生活场景。其Agent能力更在指令遵循测试中取得54.2分(HLE-Text基准),较同类模型提升近30%。
商业化落地进程显著加快。豆包App及多端平台同步上线"专家模式",接入2.0 Pro版本后,复杂内容理解、空间推理及长尾知识调用能力获得质的提升。此前引发热议的视频生成模型Seedance 2.0也已完成系统整合。定价策略凸显竞争力:Pro版按输入长度计费,32k内输入单价3.2元/百万tokens,输出16元/百万tokens;Lite版性能超越前代主力模型1.8,输入成本降至0.6元/百万tokens。
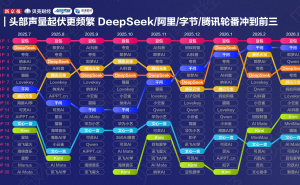
行业竞赛呈现白热化态势。2月13日,MiniMax发布文本模型MiniMax M2.5,智谱同日开源新一代旗舰模型GLM-5——该模型曾以"Pony Alpha"代号登顶OpenRouter热度榜。阿里巴巴等企业也在加速技术迭代。值得关注的是,DeepSeek被曝正在测试支持1M上下文的长文本模型,虽API服务暂维持V3.2版本(128K上下文),但此举被解读为春节技术发布的前奏,或重现去年春节的现象级突破。
技术专家指出,本轮升级潮呈现三大趋势:多模态融合加速、长上下文处理成标配、成本控制向消费级延伸。随着头部企业相继亮出技术底牌,春节假期可能成为决定全年竞争格局的关键窗口期。据不完全统计,近两周已有超过5家企业发布或预告大模型更新,涵盖文本、图像、视频及具身智能等多个赛道。